在上一篇分析了VFS的读过程,其中在函数generic_file_buffered_read()里有一段代码:
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
f_mapping对应的就是文件file在内存的信息,即page cache的数据结构。
static ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
struct file *filp = iocb->ki_filp;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
struct file_ra_state *ra = &filp->f_ra;
loff_t *ppos = &iocb->ki_pos;
pgoff_t index;
pgoff_t last_index;
pgoff_t prev_index;
unsigned long offset; /* offset into pagecache page */
unsigned int prev_offset;
int error = 0;
if (unlikely(*ppos >= inode->i_sb->s_maxbytes))
return 0;
iov_iter_truncate(iter, inode->i_sb->s_maxbytes);
index = *ppos >> PAGE_SHIFT;
prev_index = ra->prev_pos >> PAGE_SHIFT;
prev_offset = ra->prev_pos & (PAGE_SIZE-1); // PAGE_SIZE=4096, prev_offset = min(ra->prev_pos, 4095) = [0,4095]
last_index = (*ppos + iter->count + PAGE_SIZE-1) >> PAGE_SHIFT;
offset = *ppos & ~PAGE_MASK;
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
unsigned long nr, ret;
cond_resched();
find_page:
if (fatal_signal_pending(current)) {
error = -EINTR;
goto out;
}
page = find_get_page(mapping, index);//对于新文件,page为NULL
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT)
goto would_block;
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index); //由于读新文件还没有对应cache,因此不会预读
page = find_get_page(mapping, index);//再次获取page cache,还是返回NULL
if (unlikely(page == NULL))
goto no_cached_page; // page为NULL,则跳转至no_cached_page处执行
}
no_cached_page:
/*
* Ok, it wasn't cached, so we need to create a new
* page..
*/
page = page_cache_alloc(mapping);//分配新page
if (!page) {
error = -ENOMEM;
goto out;
}
error = add_to_page_cache_lru(page, mapping, index,
mapping_gfp_constraint(mapping, GFP_KERNEL));//将page添加至cache中
if (error) {
put_page(page);
if (error == -EEXIST) {
error = 0;
goto find_page;
}
goto out;
}
goto readpage;
}
would_block:
error = -EAGAIN;
out:
ra->prev_pos = prev_index;
ra->prev_pos <<= PAGE_SHIFT;
ra->prev_pos |= prev_offset;
*ppos = ((loff_t)index << PAGE_SHIFT) + offset;
file_accessed(filp);
return written ? written : error;
}
其中f_mapping类型是address_space结构,对应数据结构如下:
struct address_space {
struct inode *host;
struct xarray i_pages;
gfp_t gfp_mask;
atomic_t i_mmap_writable;
#ifdef CONFIG_READ_ONLY_THP_FOR_FS
/* number of thp, only for non-shmem files */
atomic_t nr_thps;
#endif
struct rb_root_cached i_mmap;
struct rw_semaphore i_mmap_rwsem;
unsigned long nrpages;
unsigned long nrexceptional;
pgoff_t writeback_index;
const struct address_space_operations *a_ops;
unsigned long flags;
errseq_t wb_err;
spinlock_t private_lock;
struct list_head private_list;
void *private_data;
} __attribute__((aligned(sizeof(long)))) __randomize_layout;
struct xarray {
spinlock_t xa_lock;
/* private: The rest of the data structure is not to be used directly. */
gfp_t xa_flags;
void __rcu * xa_head;
};
struct xa_node {
unsigned char shift; // shift成员用于指向当前xa_node slots的单位;
unsigned char offset; // offset表示该xa_node在父节点的slot中偏移值;
unsigned char count; // count 表示当前xa_node有多少个slot已经被使用;
unsigned char nr_values; // nr_values成员表示该xa_node有多少个slots存储的Value Entry
struct xa_node __rcu *parent; //parent 指向父节点;
struct xarray *array; // array成员指向该xa_node所属的xarray
union {
struct list_head private_list; /* For tree user */
struct rcu_head rcu_head; /* Used when freeing node */
};
void __rcu *slots[XA_CHUNK_SIZE];// slots是个指针数组, 该数组既可以存储下一级的节点, 也可以用于存储即将插入的对象指针
union {
unsigned long tags[XA_MAX_MARKS][XA_MARK_LONGS];
unsigned long marks[XA_MAX_MARKS][XA_MARK_LONGS];
};
};
page_cache_alloc()会调用alloc_pages()函数执行具体的内存分配逻辑,内存分配单位是page,一个page默认大小是4096字节。内存分配在之前的文章软中断下内存分配逻辑一文中有具体聊过内存分配逻辑,这里就不做详细赘述。
接下来重点看add_to_page_cache_lru()函数,该函数是将创建好的page加入到cache中:
int add_to_page_cache_lru(struct page *page, struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask)
{
void *shadow = NULL;
int ret;
__SetPageLocked(page);
ret = __add_to_page_cache_locked(page, mapping, offset,
gfp_mask, &shadow);//将page加入到cache
if (unlikely(ret))
__ClearPageLocked(page);
else {
/*
* The page might have been evicted from cache only
* recently, in which case it should be activated like
* any other repeatedly accessed page.
* The exception is pages getting rewritten; evicting other
* data from the working set, only to cache data that will
* get overwritten with something else, is a waste of memory.
*/
WARN_ON_ONCE(PageActive(page));
if (!(gfp_mask & __GFP_WRITE) && shadow)
workingset_refault(page, shadow);
lru_cache_add(page);
}
return ret;
}
__add_to_page_cache_locked()函数将page插入到page cache中,由于本文是基于linux5.5内核版本,因此page cache使用的是xarray数据结构实现(4.20版本之前使用的radix tree结构实现)。
// page:页面描述符指针,该页面中有文件数据;
// mapping:address_space对象指针
// offset:表示该页在文件的页面索引
static int __add_to_page_cache_locked(struct page *page,
struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask,
void **shadowp)
{
XA_STATE(xas, &mapping->i_pages, offset);
int huge = PageHuge(page);
struct mem_cgroup *memcg;
int error;
void *old;
VM_BUG_ON_PAGE(!PageLocked(page), page);
VM_BUG_ON_PAGE(PageSwapBacked(page), page);
mapping_set_update(&xas, mapping);
if (!huge) {
error = mem_cgroup_try_charge(page, current->mm,
gfp_mask, &memcg, false);
if (error)
return error;
}
get_page(page);
page->mapping = mapping;
page->index = offset;
// 对xarray操作,将新page加入到page cache
do {
xas_lock_irq(&xas);
old = xas_load(&xas);
if (old && !xa_is_value(old))
xas_set_err(&xas, -EEXIST);
xas_store(&xas, page);
if (xas_error(&xas))
goto unlock;
if (xa_is_value(old)) {
mapping->nrexceptional--;
if (shadowp)
*shadowp = old;
}
mapping->nrpages++;
/* hugetlb pages do not participate in page cache accounting */
if (!huge)
__inc_node_page_state(page, NR_FILE_PAGES);
unlock:
xas_unlock_irq(&xas);
} while (xas_nomem(&xas, gfp_mask & GFP_RECLAIM_MASK));
if (xas_error(&xas))
goto error;
if (!huge)
mem_cgroup_commit_charge(page, memcg, false, false);
trace_mm_filemap_add_to_page_cache(page);
return 0;
error:
page->mapping = NULL;
/* Leave page->index set: truncation relies upon it */
if (!huge)
mem_cgroup_cancel_charge(page, memcg, false);
put_page(page);
return xas_error(&xas);
}
对于xarray相关的增删查改等操作函数就不详细阐述了,这里以图例的方式展示对xarray的操作过程,这样会更直观。 初始化xarray:
 首次插入page后的图示:
首次插入page后的图示:
 再插入page后的图示:
再插入page后的图示:
当插入page时,xarray的高度需要增加1,即:
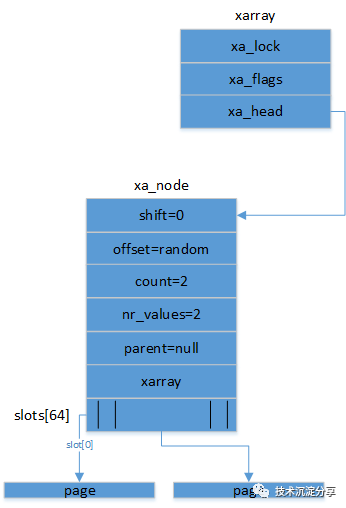 后续对于新增和删除都可能会涉及到xarray的结构变化,其实这里还是叫tree会更合适,即tree高度的变化。
后续对于新增和删除都可能会涉及到xarray的结构变化,其实这里还是叫tree会更合适,即tree高度的变化。
由于本文是基于linux5.5内核版本,因此默认使用xarray实现page cache的存储结构,在linux4.20版本之前是使用radix tree实现page cache的存储结构,radix tree和xarray结构类似,准确的说是操作方法是类似的,只不过节点结构由tree改为了array。
其实先了解radix tree再回过头来看xarray会简单些,因为思想是一样的,只不过xarray做了统一的封装和优化。